文字の図形的な埋め込み表現 Glyph-aware Character Embedding
2018-07-25

「文字の図形的な埋め込み表現」は、文字の図形的な情報から埋め込み表現を学習したデータセットです。文字の意味や文章中の文脈などのセマンティクスから構成する分散表現とは違い、文字の形状という視覚的な特徴を学習しています。それぞれの文字に対する埋め込み表現の近さを計算することで、似た形の文字を推定することができます。
ダウンロード
下記のGitHubレポジトリからダウンロード可能です。以下のURLを開いて「Download」をクリックしてください。
convolutional_AE_300.tar.bz2 (解凍前:88MB, 解凍後:180MB)
以下の2つのファイルが入っています。フォーマットが異なるだけで、どちらも同じベクトルデータです。
convolutional_AE_300.binconvolutional_AE_300.txt
その他サンプルコードなどのすべてのファイルは、以下のレポジトリにあります。
yagays/glyph-aware-character-embedding
詳細
- ベクトル次元:
300 - 文字の種類数:
44,637 - 学習データに用いたフォント:Google Noto Fonts
NotoSansCJKjp-Regular
使い方
gensimを用いた利用方法を例示します。なお、ここではword2vecのように単語の分散表現として扱っていますが、本リソースで扱う文字の図形的な埋め込み表現には加法性がありません。図形としての文字の類似度は計算できますが、部首の足し算引き算といったような操作はできないのでご注意下さい。
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format("data/convolutional_AE_300.bin", binary=True)
most_similar()を用いて、図形的な類似文字を検索します。以下の例では一番類似度が高い文字に「а」が来ていますが、これはasciiの「a」ではなくキリル文字の「a」です。
In []: model.most_similar("a")
Out[]:
[('а', 1.0000001192092896),
('ả', 0.961397111415863),
('ä', 0.9610118269920349),
('ā', 0.9582812190055847),
('á', 0.957198441028595),
('à', 0.9558833241462708),
('å', 0.938391923904419),
('ầ', 0.9370290040969849),
('ǎ', 0.9368112087249756),
('ấ', 0.9365179538726807)]
Google Noto Fonts NotoSansCJKjp-Regularに含まれるすべての文字に対して操作が可能です。
In []: model.most_similar("油")
Out[]:
[('汕', 0.9025427103042603),
('泊', 0.8892871737480164),
('伷', 0.884428083896637),
('浊', 0.8678311109542847),
('沖', 0.8532482385635376),
('沽', 0.8451510667800903),
('沺', 0.8355003595352173),
('沾', 0.8313066959381104),
('涃', 0.8284391164779663),
('泩', 0.8275920152664185)]
ユニコードには同じような外見で異なるコードポイントが割り当てられているものが存在します。それらを区別する際には、ord()で数値への変換を行うか、unicodedata.name()で文字の名前を表示するのが有効です。
In []: for char, score in model.most_similar("は", topn=15):
...: print("\t".join([char, str(score), hex(ord(char)), unicodedata.name(char, "UNKNOWN")]))
"け" 0.8354311585426331 0x3051 HIRAGANA LETTER KE
"ほ" 0.8342610597610474 0x307b HIRAGANA LETTER HO
"げ" 0.7546985745429993 0x3052 HIRAGANA LETTER GE
"ば" 0.7366447448730469 0x3070 HIRAGANA LETTER BA
"ぱ" 0.7308192253112793 0x3071 HIRAGANA LETTER PA
"に" 0.7154880166053772 0x306b HIRAGANA LETTER NI
"⒑" 0.7061284780502319 0x2491 NUMBER TEN FULL STOP
"냐" 0.6923456192016602 0xb0d0 HANGUL SYLLABLE NYA
"댜" 0.682737410068512 0xb31c HANGUL SYLLABLE DYA
"⒙" 0.6763017773628235 0x2499 NUMBER EIGHTEEN FULL STOP
"砂" 0.6754936575889587 0x7802 CJK UNIFIED IDEOGRAPH-7802
"⒔" 0.6732239723205566 0x2494 NUMBER THIRTEEN FULL STOP
"탅" 0.6726106405258179 0xd0c5 HANGUL SYLLABLE TANJ
"㢟" 0.6707605719566345 0x389f CJK UNIFIED IDEOGRAPH-389F
"叵" 0.6700443029403687 0x53f5 CJK UNIFIED IDEOGRAPH-53F5
Kerasなどに利用できる埋め込み層の作成方法は、下記サンプルコードを参照下さい。
glyph-aware-character-embedding/example at master · yagays/glyph-aware-character-embedding
手法
訓練
文字の図形的な埋め込み表現を得るために、文字を画像としてデータ化した上でConvolutional AutoEncoderを利用しました。AutoEncoderは入力と出力が同じ値になるようなニューラルネットで、構造として入力層/出力層よりも次元数の少ない中間層を持つことで、低次元での表現を学習することができます。
学習データの作成においては[Su and Lee , 2017]を参考に、利用したフォントが図形として描写可能なすべての文字に対して、背景が黒色で文字が白色の60x60の画像を作成しました。学習の際には、画像をグレースケールに変換後に正規化しました。
Convolutional AutoEncoderの構造は、中間層を300次元として両側を畳み込みと逆畳み込みによって構成しています。中間層の次元数は、なるべく小さい値でかつ学習時のvalidation lossが小さくなるものを実験的に検証して選択しました。最適化にはAdamを、損失関数にはMSEを用いました。epoch数は100に固定した上で、Early-stoppingによりvalidation lossが下がりきった際に学習を終了しています。また、訓練データとテストデータを9:1に分割し、訓練データのみで学習を行いました。
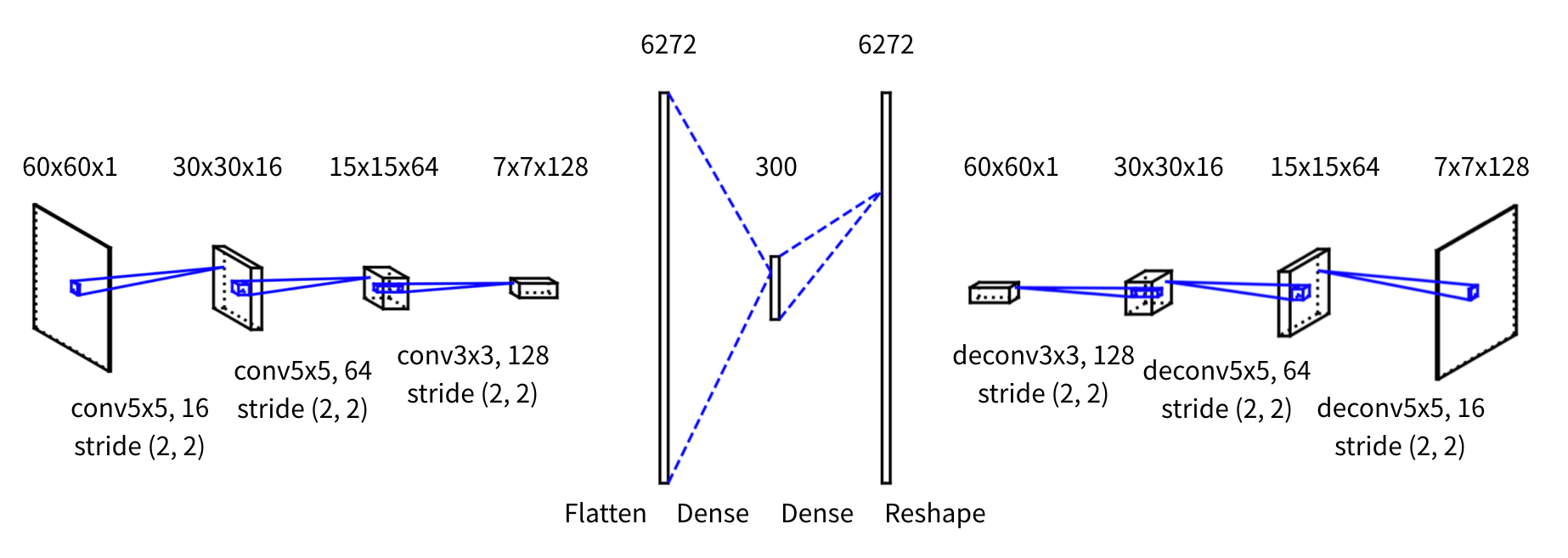 Fig. Convolutional AutoEncoderの概念図
Fig. Convolutional AutoEncoderの概念図
評価
テストデータの文字をConvolutional AutoEncoderで復元した結果は、以下のようになりました。中国語や韓国語、図形的な丸囲いの文字など、おおよそ文字を再構成できていることがわかります。
 Fig. 上段:convAEに入力された画像 下段:convAEで出力された画像
Fig. 上段:convAEに入力された画像 下段:convAEで出力された画像
可視化
可視化の手法を別記事にて追加しました。TensorBoardを用いてt-SNEによる低次元での可視化の方法を記載しています。
Out-of-the-box - 学習済み分散表現をTensorBoardで可視化する (gensim/PyTorch/tensorboardX)
ライセンス
CC-BY
このリソースはクリエイティブ・コモンズ 表示 4.0 国際 ライセンスの下に提供されています。
クレジット
参考
論文
- Document classification through image-based character embedding and wildcard training - IEEE Conference Publication
- [1708.04755] Learning Chinese Word Representations From Glyphs Of Characters
- [1709.00028] Glyph-aware Embedding of Chinese Characters
- Deep Clustering with Convolutional Autoencoders | SpringerLink
- [1704.04859] Learning Character-level Compositionality with Visual Features
ウェブ
- Kerasで学ぶAutoencoder
- PytorchによるAutoEncoder Familyの実装 - 前に逃げる
- Pythonで日本語の文字分散表現を学習する - 自然言語処理の深遠
- Pretrained Character Embeddings for Deep Learning and Automatic Text Generation



