学習済み分散表現をTensorBoardで可視化する (gensim/PyTorch/tensorboardX)
2018-08-28
word2vecや系列モデル等で学習した分散表現の埋め込みベクトル(word embeddings)は、単語の意味をベクトル空間上で表現することが可能です。最も有名な例では「King - Man + Woman = Queen」のように意味としての加算や減算がベクトル計算で類推可能なこともあり、ベクトル空間の解釈として低次元へ写像する形で分散表現の可視化が行われています。
可視化の際に用いられるツールとしては、TensorFlowのツールの一つであるTensorBoardが、豊富な機能とインタラクティブな操作性を備えていて一番使い勝手が良いと思います。ただ、TensorFlowと組み合わせた可視化は容易なのですが、他のツールやパッケージで作成したコードをそのまま読み込めないなど、かゆいところに手が届かないと感じる部分もあります。
そこで今回は、すでに学習された単語の分散表現を可視化するために、
- gensimを用いてベクトルを読み込み、
- PyTorchのTensor形式に変換したうえで、
- tensorboardXを用いてTensorBoardが読み込めるログ形式に出力する
ことで、TensorBoard上で分散表現を可視化します。いろいろなステップがあって一見して遠回りに思えますが、コード自体は10行に満たないほどで完結します。個人的には、Tensorflowで学習済み分散表現を読み込むよりも、これらを組み合わせたやり方のほうが簡潔に書くことができて好きです。
方法
準備
必要な外部パッケージは、gensim/pytorch/tensorboardX/tensorflowの4つです。インストールされていない場合はpipなどであらかじめインストールしておきます。
$ pip isntall gensim torch tensorboardX tensorflow
分散表現の読み込みからtensorboard形式のログ出力まで
TensorBoardで可視化するまでに必要な本体のコードです。これだけ!
import gensim
import torch
from tensorboardX import SummaryWriter
vec_path = "entity_vector.model.bin"
writer = SummaryWriter()
model = gensim.models.KeyedVectors.load_word2vec_format(vec_path, binary=True)
weights = model.vectors
labels = model.index2word
# DEBUG: visualize vectors up to 1000
weights = weights[:1000]
labels = labels[:1000]
writer.add_embedding(torch.FloatTensor(weights), metadata=labels)
コード内のvec_pathは、任意の学習済みベクトルのファイルに置き換えてください。
また、途中で差し込まれているDEBUGの部分では、TensorBoardの読み込みスピード等を考慮して対象単語数を1000に絞っています。本来ならばこのような操作は不要ですが、かといってすべてのベクトルをTensorBoardで読み込んだとしても、デフォルトではランダムに10万件しか表示されません。学習済み分散表現の単語数があまりにも多い場合は、自分の可視化したい単語等に限定するなど少し工夫が必要です。
Embedding projector only loads first 100,000 vectors · Issue #773 · tensorflow/tensorboard
TensorBoardで可視化
上記スクリプトを実行すると、実行されたディレクトリにruns/が作成されます。TensorBoardの起動時にrunsディレクトリを指定することで、変換した単語の分散表現が可視化できます。
$ tensorboard --logdir=runs
上記コマンドを実行した状態で http://localhost:6006/ にアクセスすると、PROJECTORのページにてグラフが確認できます。
可視化の事例
日本語 Wikipedia エンティティベクトル
可視化の具体例として、日本語 Wikipedia エンティティベクトルを可視化してみます。
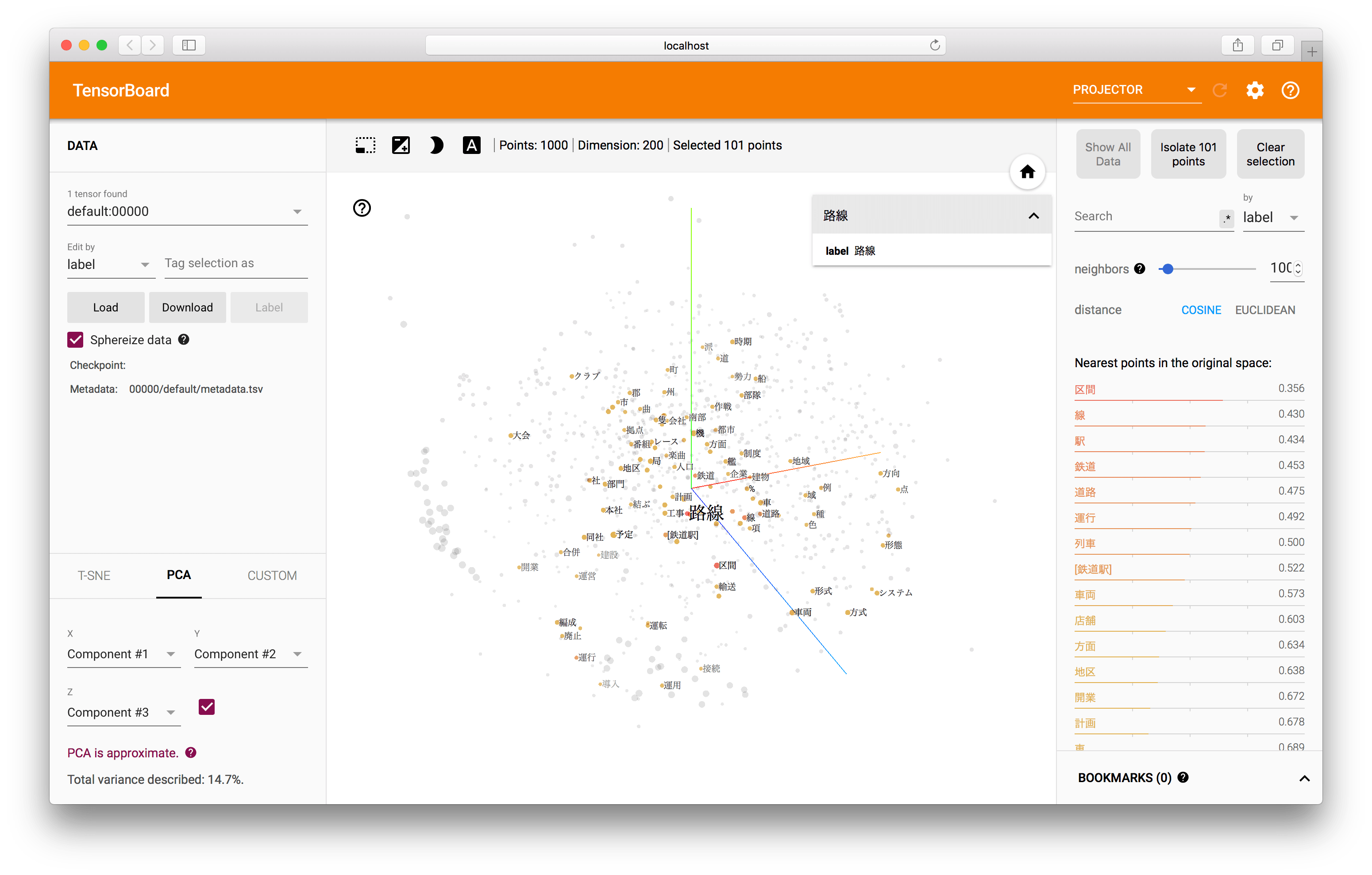
これはPCAでの可視化の事例です。3次元上の点をクリックすると、その単語の情報とともに、類似した点のラベル情報も同時に確認することができます。ここでは「路線」という点をクリックしており、それに対応する類似単語が中央の3次元グラフ上でも右側のリストでも表示されています。
3次元グラフ上ではまとまりがあまり無いように見えますが、これはPCAで3次元に圧縮したものを可視化しているためです。TensorBoardに用意されているもう一つの次元圧縮の手法であるT-SNEを使うことで、より類似した単語が3次元空間上で近い位置に配置されるように可視化されます。
文字の図形的な埋め込み表現
また、画像を含めた可視化も可能です。本サイトで公開している文字の図形的な埋め込み表現でも同様に可視化をしてみます。画面上で黒い四角の文字が表示されていますが、これはあらかじめ用意してあった画像を読み込んでいるためです。
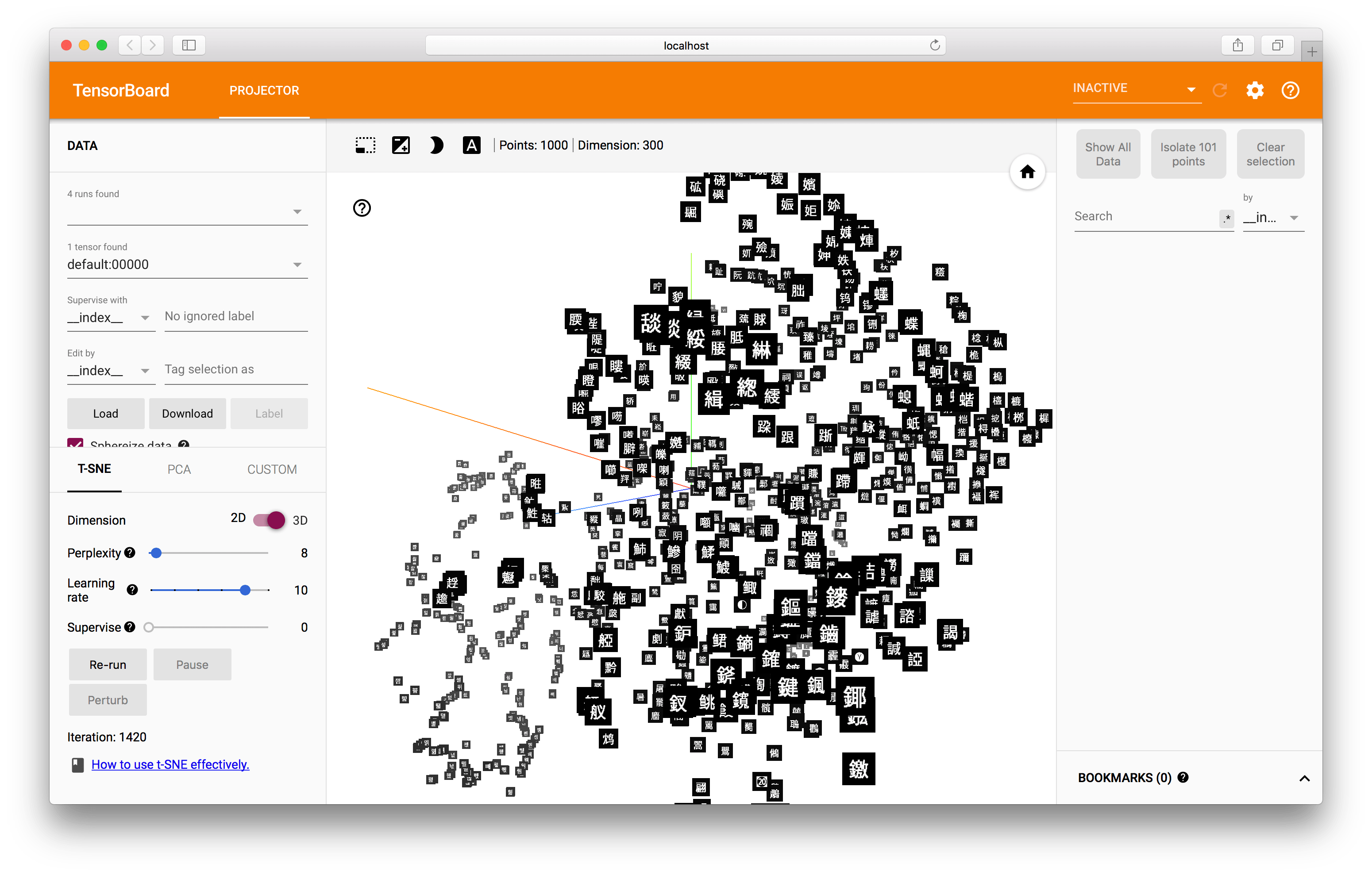
ここで使用しているTensorBoardの変換のためのコードは、以下から取得可能です。
応用:分散表現以外にも利用する
この可視化は単語の分散表現以外にも、ユニークなIDやラベルに対して固定長のベクトルが割り当てられていれば、一般的な特徴量やベクトル表現にも応用できます。
gensimでロードできるファイルは、オリジナルのword2vecで扱われるファイルフォーマットです。gensimではword2vec C formatと呼ばれています。
構造的には単純で、1行目にメタデータ、2行目からベクトル情報が列挙されます。1行目の始めにはベクトルの数と次元数(MxN行列のMとN)を記述します。2行目からは、行頭に対応する単語なりIDなどのユニークな名前、以降はスペース区切りで数値が並びます。
40000 300
id_1 -0.117995 0.131594 0.478000 ...
id_2 -0.729706 -0.069133 -0.014612 ...
id_3 0.033804 0.005422 -0.172256 ...
...
id_40000 0.190483 0.077391 -0.139530 ...



