Word Embedding based Edit Distanceの実装
2018-11-12

Leading NLP Ninjaのep.12で紹介されていたWord Embedding based Edit Distanceを実装してみました。
Word Embedding based Edit Distance
Word Embedding based Edit Distance(WED)は、文字列間の類似度を計算する編集距離(Edit Distance)を拡張して、単語埋め込みの類似度を使うことによって文章間の意味的な距離を編集距離的に計算しようというものです。編集距離では文字の追加/削除/置換のコストが1なのに対し、WEDではそれぞれのコストは以下のように設定しています。問題は単語埋め込みの類似度をどう使うかですが、追加と置換のコストに関しては対応する文中に近い単語があればそっちの類似度分をコスト1から差し引く、置換に関しては単語間の類似度を単純にコストから差し引くといった形で拡張しています。
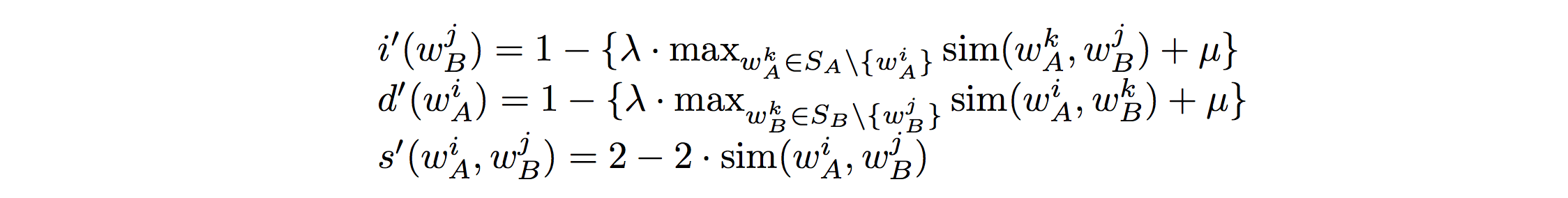
ここで、単語間の類似度は以下のように計算しています。
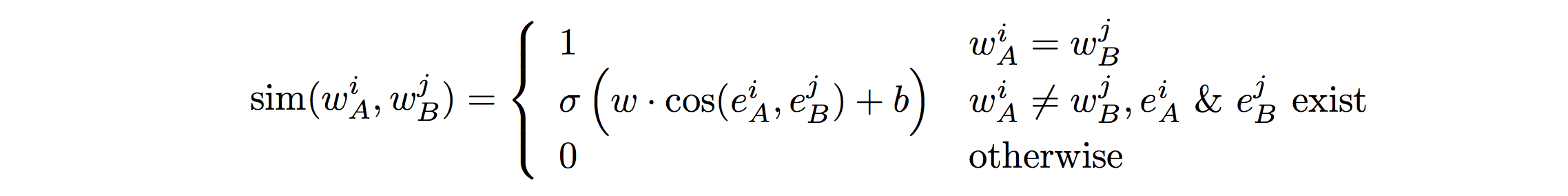
なので、このアルゴリズムに出てくるパラメータはw,b,λ,μの4つです。
詳しくはLeading NLP Ninjaの解説の方を参照ください。
実装
yagays/wed: Python implementation of Word Embedding based Edit Distance
基本的には編集距離の実装に用いる動的計画法をそのままに、コスト部分を論文通りに拡張すればOKです。ただし、実装が合っているかどうかすごく不安なので、あくまで参考適度に……。
注意点として、DPの配列の0行目と0列目では片方の文字列を削除したときのコストが入るので、単純に行/列ごとに1をインクリメントしていくのではなく、上記コストを計算する必要があります。
評価
流石に論文のような評価はしていませんが、手元でSTAIR Captionsを対象に類似度計算をした結果、まあまあ妥当そうな結果になりました。ここでは15,000件くらいの文章を対象に、馬が走っているという文章に似た文章を近い順に10件列挙しています。
[['一頭の茶色い馬が走っている', 0.6571005980449359],
['芝生の上を人がのった馬が走っている', 1.073464996815989],
['黄色いスクールバスが走っている', 1.0986647573718564],
['道路を首輪をした白い馬が走っている', 1.1281587567774887],
['尻尾の長い茶色の馬が歩いている', 1.1786151622459524],
['汽車のミニチュアが走っている', 1.2233853716174816],
['車の外を白や茶色の馬が走っている', 1.2432452098145987],
['大きな道路をトラックが走っている', 1.2456263623812807],
['フリスビーをくわえた犬が走っている', 1.2533987344007116],
['曲がりくねった道をレーサーが走っている', 1.2657003314558781]]
感想
実装/評価する上で気になった点を幾つか。
1. 追加/削除のコスト
まずはじめに気になる点として、WEDの追加/削除のコスト計算がそれで良いのか問題。今回の論文の計算方法では、文章中の全単語の中から最も近い単語の類似度を用いるので、文中でどれだけ離れていても一番意味的に近い単語が採用される点が気になります。文章が長ければ長いほど似た単語が現れやすいでしょうし、編集距離を拡張している意味が何なのかよくわからなくなってきます。一度類似した単語として利用したら以降は使わないとか、前後n単語のみの類似度を使うとか、もう少し改良が必要な気がします。
2. パラメータ調整
そもそも最適なパラメータ調整がかなり難しいです。追加/削除と置換のコストがバランス取れていないと一単語置換するより1単語削除して1単語追加したほうが良いみたいになることもあり、この辺ピーキーすぎて調整が難しいところ。単語間類似度を計算するときにcos類似度→[0,1]の類似度に変換している部分も、改良の余地があると思います。
3. 文字列間の文章長の影響
また、極端に短い文章を対象にすると、意味的に関係が無くてもトータルのコストが低くなる場合があります。このあたりはコスト周りのパラメータの調整でも限界があると思うので、Quoraの質問ペアのようなある程度整ったデータセットでないと辛い部分でしょう。といってもそこは従来の編集距離でも同じことなので、的外れな意見ではあります。
4. 計算コスト
論文中には計算量は編集距離と同じとありますが、追加/削除の類似度計算は比較する文章中の単語数だけ必要です。また、基本的には与えられた文章ペアの類似度を計算する方法なので、ある一つのクエリ文章に対して類似した文章を大量の候補の中から検索するといった用途には活用しにくいと思います。
まとめ
単語埋め込みを元にした意味的な近さを編集距離に持ち込んだWord Embedding based Edit Distanceを実装しました。論文自体のやりたいこともわかるし発想は面白いものの、なかなか結果に結びついていないのが難しいところです。これならば単純に単語ベクトルを足し合わせて文章ベクトルを作るやり方の方が、計算コストも軽く類似度計算も高速で良いかなと思ってしまいます。なにか上手い使い方があれば今後使ってみたいですね。
参考
- [1810.10752] Word Embedding based Edit Distance
- 本記事の図表は、この論文から引用されたものです
- ep12: Word Embedding based Edit Distance by Leading NLP Ninja • A podcast on Anchor
- 2018: Word Embedding based Edit Distance · Issue #145 · jojonki/arXivNotes
- レーベンシュタイン距離 - Wikipedia
- いまさら編集距離 (Levenshtein Distance) を実装するぜ | takuti.me



