SWEM: 単語埋め込みのみを使うシンプルな文章埋め込み
2019-05-29
単語埋め込み (Word Embedding) のみを利用して文章埋め込み (Sentence Embedding) を計算するSWEM (Simple Word-Embedding-based Methods) を実装しました。
概要
文章に対する固定次元の分散表現を得る手法としては、doc2vecやSkip-thoughts、テキスト間の含意関係を学習することで分散表現を得るinfersent、最近では強力な言語モデルとなったBERTといった方法があります。これらの手法は、単語ベクトルに加えて文章ベクトルを得るためのニューラルネットワーク自体を、大規模コーパスから学習させる必要があります。
そこで、より単純ながらも後続タスクへの精度がでる文章埋め込みの計算方法として、追加学習やパラメータチューニングを必要とせず単語埋め込みだけを利用するSWEMが提案されました。これはACL2018 “Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms”にて発表された方法で、複数のデータセットにおける評価において、既存のCNN/RNNモデルと同等またはそれ以上の精度となっています。ロジックは単純ながらもある程度良い性能を示すことから、強力なベースラインとして利用することができると考えられます。
方法
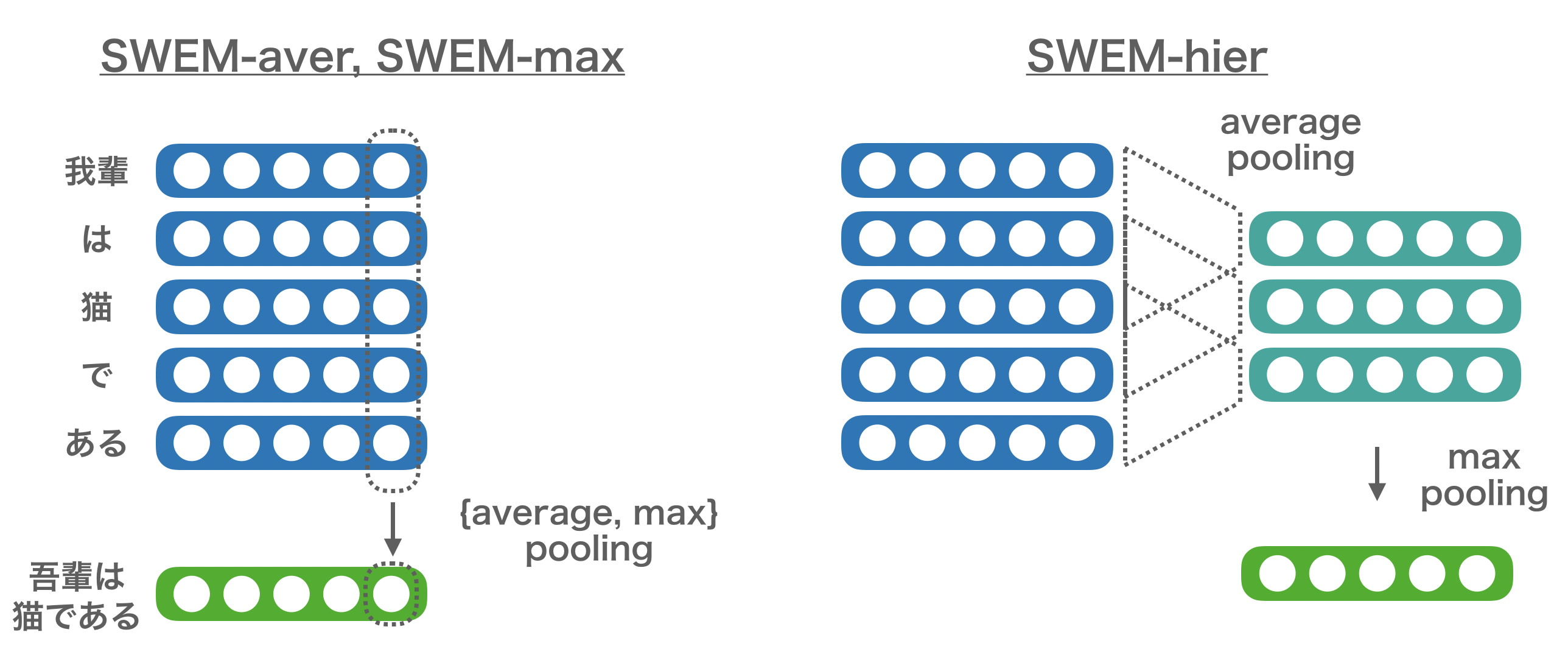
SWEMでは以下の4つの方法が提案されています。
SWEM-aver:単語の分散表現に対してaverage poolingするSWEM-max:単語の分散表現に対してmax poolingするSWEM-concat:SWEM-averとSWEM-maxの結果を結合するSWEM-hier:n-gramのように固定長のウィンドウでaverage-poolingした結果に対してmax poolingする
これらは基本的に、文章に含まれる単語の分散表現全体に対して、どういう操作で固定時点のベクトルに集約するかといった操作の違いでしかありません。それぞれのaverage poolingやmax poolingは、element-wiseにaverageやmaxを取ります。Out-of-Vocabulary (OOV) な単語に対しては、[-0.01, 0.01]の範囲の一様乱数を用いて初期化します。なお、aver, max, concatに関してはパラメータはありませんが、SWEM-hierはn-gramのウィンドウの幅nを決める必要があります。
ちなみに、結局のところどれが一番いいの?という話ですが、論文中の評価ではタスク/データ依存という結果になっており、一概にどれが良いかは断定できないようです。
コード
from gensim.models import KeyedVectors
from swem import MeCabTokenizer
from swem import SWEM
w2v_path = "/path/to/word_embedding.bin"
w2v = KeyedVectors.load_word2vec_format(w2v_path, binary=True)
tokenizer = MeCabTokenizer("-O wakati")
swem = SWEM(w2v, tokenizer)
In []: text = "吾輩は猫である。名前はまだ無い。"
# SWEM-aver
In []: swem.average_pooling(text)
Out[]:
array([ 2.31595367e-01, 5.31529129e-01, -6.28219426e-01, -7.73212969e-01,
5.56734562e-01, 5.50618172e-01, 7.96405852e-01, 1.65987098e+00,
[...]
# SWEM-max
In []: swem.max_pooling(text)
Out[]:
array([ 1.4522485e+00, 2.1016493e+00, 9.1187710e-01, 6.2075871e-01,
2.7146432e+00, 2.6316767e+00, 2.3899646e+00, 3.0643713e+00,
[...]
# SWEM-concat
In []: swem.concat_average_max_pooling(text)
Out[]:
array([ 2.31595367e-01, 5.31529129e-01, -6.28219426e-01, -7.73212969e-01,
5.56734562e-01, 5.50618172e-01, 7.96405852e-01, 1.65987098e+00,
[...]
# SWEM-hier
In []: swem.hierarchical_pooling(text, n=2)
Out[]:
array([ 1.08240175e+00, 1.80855095e+00, 2.49545574e-02, 3.06840777e-01,
1.25868618e+00, 1.97042620e+00, 1.59599078e+00, 2.99531865e+00,
[...]



