単語埋め込みにおけるout-of-vocabularyの対応 - magnitudeの初期化
2019-02-27

概要
magnitudeという単語埋め込みを扱うライブラリには、単語を構成する文字列を考慮したout-of-vocabularyの初期化の方法が実装されています。EMNLP 2018の論文と実際のコードを元に、その初期化の方法を実装して試してみました。
背景
KaggleのQuora Insincere Questionsコンペを終えて
KaggleのQuora Insecure QuestionsのコンペではOOVの対応が重要だったっぽいけど、magnitudeはランダムベクトルの付与とかミススペルの対応とかしてくれるみたいだ。ロジック確認しないと何してるのかわからないけど…… https://t.co/d8tteqwwCp
— やぐ (@yag_ays) February 26, 2019
KaggleのNLPコンペであるQuora Insincere Questions Classificationが終わって上位陣の解法を眺めていたのですが、その中で目に止まったのがout-of-vocabulary(以降OOVと表記)の対応です。今回のコンペでは主催側が定めた幾つかの学習済み単語埋め込みしか使うことができないので、大規模コーパスから新しく学習することができません。そのため、データセットには含まれているが学習済み単語ベクトルには含まれていない単語であるout-of-vocabularyをどう扱うかが、前処理の重要な要素だったようです。それぞれの解法には以下のようなコメントが記載されています。
- “The most important thing now is to find as many embeddings as possible for our vocabulary. (中略) For public test data we had around 50k of vocab tokens we did not find in the embeddings afterwards. " (1st place solution)
- “I applied spell correction to OOV words.” (2nd place solution)
- “Try stemmer, lemmatizer, spell correcter, etc. to find word vectors” (3rd place kernel)
興味深いのが3位のkernelのこの部分のコードで、単語ベクトルが見つからなかった場合にひたすら単語の表記をあれこれ変えて辞書に当てる努力をしています。
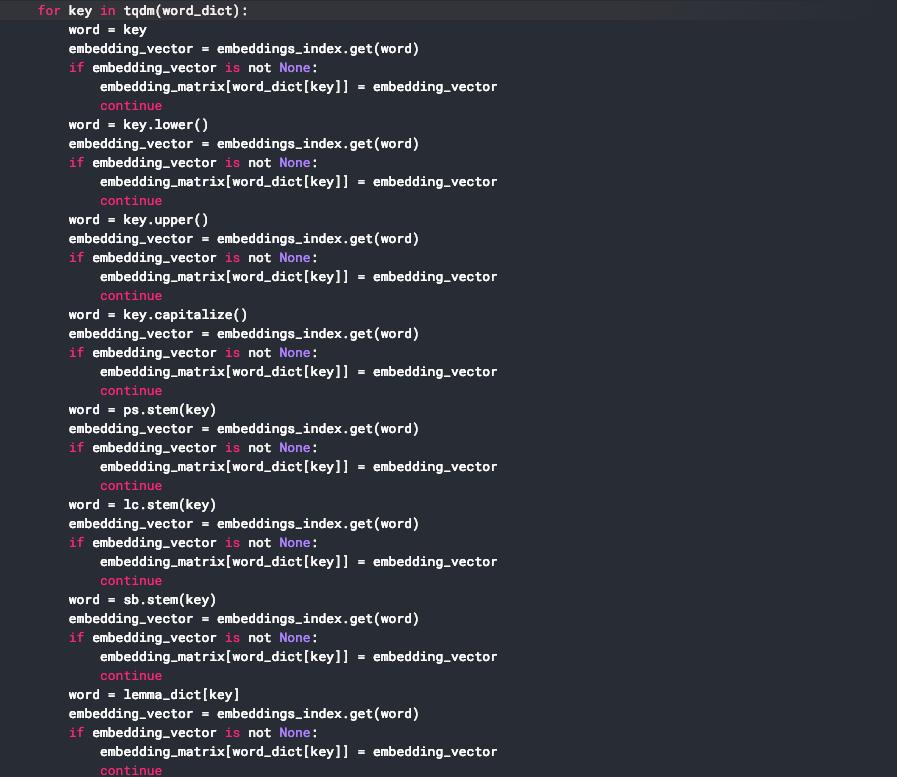 (https://www.kaggle.com/wowfattie/3rd-place#L148)
(https://www.kaggle.com/wowfattie/3rd-place#L148)
これらの努力は当然といえば当然で、近年の単語id(またはone-hot表現)から埋め込み層を経て再帰的ニューラルネットワークに流れるNNの場合では、対応する埋め込み表現が無い単語に関しては、その単語が欠損していると何ら変わらない状態になります。特に意味的な冗長さが少ない今回のコンペのようなテキストでは、含まれる単語の埋め込み表現が得られないと文章全体の表現として致命的である場合があると想像されます。低頻度語や固有名詞の場合では影響は少ないですが、こういったOOVの情報の損失はなるべく避けたいというのが戦法の一つだったと思われます。
magnitudeにおけるOOVの扱い
さて、OOVの対応事例をいろいろと見ているなかで、magnitudeというPythonパッケージにおいて特徴的なOOV対策がされているのを見つけました。基本的にはOOVにはランダムなベクトル表現を付与するのですが、下記の2つの工夫が入っています。
- 文字列的に似ているOOVの単語同士には、なるべく似たベクトル表現を付与したい
- e.g. uberの車種である
uberxとuberxlは、似た文字列であるから似たランダムベクトルになってほしい (OOVだけど意味的に似ていると想定される)
- e.g. uberの車種である
- OOVと文字列的に似ている単語が語彙中の中にあれば、そのベクトル表現と似たベクトル表現を付与したい
- e.g.
uberxというOOVは、uberが分散表現の語彙の中にあれば、それに近いランダムベクトル表現であってほしい (単語を構成する部分文字列の意味と似ていると想定される)
- e.g.
今回はこの2つのロジックについて、EMNLP 2018にてmagnitudeの開発メンバーが発表した論文と、実際のmagnitudeの実装を参考にして、最低限な要素のみを取り出して実装してみました。
magnitudeのロジック
magnitudeでは、OOVのベクトルは下記式のように2つの項から構成されています。
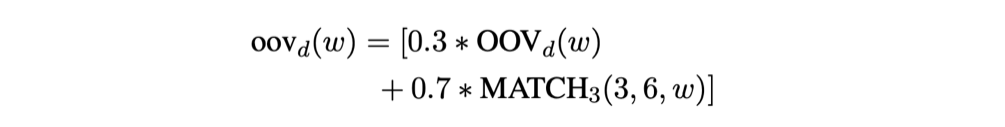 (本文中の数式は https://arxiv.org/pdf/1810.11190.pdf より引用)
(本文中の数式は https://arxiv.org/pdf/1810.11190.pdf より引用)
1項目OOVの計算
まず1つ目のOOV_d(w)は、文字列からどうやってランダムなベクトルを作るかという部分です。これまた以下のような定義式で計算するのですが、
- CGRAM_w(3,6)では、単語における3-gramから6-gramまでの文字列をすべて列挙する
- oov_d(w)では、列挙したngramの文字列全部に対して、その文字列→数字に変換した値を疑似乱数のシードとしたときに、[-1,1]の一様乱数からd次元分のランダムベクトルを作成しその平均を取る
- 最後にノルムで正規化する
という構造になっています。
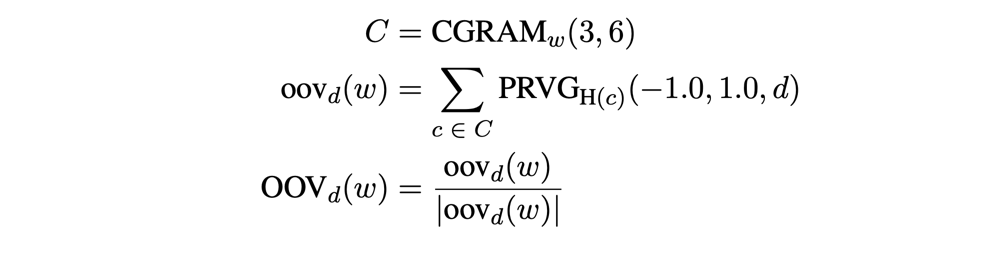
なぜこのような回りくどい方法を取るかと言うと、1つ目の目的であった「文字列的に似ているOOVの単語同士には、なるべく似たベクトル表現を付与したい」に関連します。1.のngramの生成は、Pythonでの実装は以下のようになります(ngram()の実装は省いています)。
In [ ]: def character_ngram(word, n_begin=3, n_end=5):
...: output = []
...: n = n_begin
...: while n <= n_end:
...: output += ngram(word, n)
...: n += 1
...: return output
In [ ]: character_ngram("uberx")
Out[ ]: ['ube', 'ber', 'erx', 'uber', 'berx', 'uberx']
In [ ]: character_ngram("uberxl")
Out[ ]: ['ube', 'ber', 'erx', 'rxl', 'uber', 'berx', 'erxl', 'uberx', 'berxl']
こうやって見ると、文字列で見たときに似ている単語同士は、当然ながらそのngramの構成も近くなります。あとは、各ngramから何かしらのランダムベクトルが計算できれば、その足し合わせで表現することでランダムベクトルも近くなるはずです。なので、文字列を数字に変換した上で、それをシードとして一様乱数から分散表現の次元数分だけサンプリングすれば良いわけです。uberxとuberxlのngramで異なる部分は3つだけですので、その分少しだけ違うランダムさが加わったベクトルになります。これを論文では"pseudorandomvector generator"と呼んでいます。
2項目MATCHの計算
そして2つ目の構成要素のMATCH_3(3,6,w)では、与えられた単語に近い単語トップ3を抽出し、その平均を取ります。magnitudeのコード内ではSQLiteの機能を利用して類似文字列を検索したり、特定のパターンを元に単語の部分文字列を抽出しています。
そして、これらの2つを30%と70%の重みで足し合わせることで、最終的なランダムベクトルを計算します。
実装
magnitudeのコードを参考に、一部日本語の正規化のロジックも入れて実装しました。
以下のように利用できます。
from oov import MagnitudeOOV
model = KeyedVectors.load_word2vec_format("/path/to/jawiki.word_vectors.200d.bin", binary=True)
moov = MagnitudeOOV(word2vec=model)
# ベクトルの作成
moov.query(query_1)
# 類似単語の列挙
model.similar_by_vector(moov.query(query_1))
なお、英語→日本語の変換の過程で見出し語化などの特定の処理は行っておらず、また文字列の類似度計算には編集距離を用いています。magnitudeの完全な移植ではないのでご了承ください。
テスト
具体的なタスクでの精度向上みたいな話はなかなかできないので、ここでは幾つかのOOVの初期化の結果を示します。
例1
まず、文字列が似ている単語同士が近い距離になるかを確かます。「前前前世」という語彙中に存在する単語に対して、「前前前前世」と「前前前前前世」というOOVのランダムベクトルを作成しました。
その結果コサイン距離は0.98となり、それぞれ独立したOOVながらも、それらの距離が近くなるような初期化ができました。
cosine similarity between 前前前前世 and 前前前前前世: 0.9823038957021559
また、語彙中で類似する単語トップ10をそれぞれ列挙したのが以下になります。ランダムベクトルなので、全然関係ない単語が列挙されていてランダムなベクトルでありながらも、「前前前世」という単語もその中に含まれていることがわかります。
0: やあやあ やあやあ
1: メェ 高鳴っ
2: 高鳴っ 前前前世
3: 前前前世 メェ
4: カミ様 闘演
5: ご自愛ください カミ様
6: ダンシングディーヴァ 嘘も方便
7: ぃっ スカポンタン
8: 花一匁 アルマナク
9: ヤジキタ ダンシングディーヴァ
例2
ngramに幾つもの単語が含まれる場合も試してみます。「見える化傾向」というOOVを入れると、「見え」「見える」「見える化」など、その意味を表すようなベクトルに近いものが得られていることが分かります。
model.similar_by_vector(moov.query("見える化傾向"))
Out[10]:
[('見え', 0.7801039814949036),
('見える', 0.7650930881500244),
('写し出し', 0.658745527267456),
('見える化', 0.654805064201355),
('みえる', 0.6463974714279175),
('映せる', 0.644141435623169),
('マチマチ', 0.6435281038284302),
('俯瞰的', 0.6420310735702515),
('落とし込め', 0.6353403329849243),
('見飽き', 0.6347818374633789)]
追記
論文中にもちらっと書いてあるんですが、GloVeとかword2vecとか古いモデルでも使えるというところだけがメリットだと思います。
— やぐ (@yag_ays) February 28, 2019
基本はsentencepieceとかfasttextなどのsubwordで対応していくのが今後の主流なんじゃないですかねー。



