MeCabの形態素解析の結果から正規表現を使って品詞列を抜き出すmecabpr
2019-04-15

MeCabの形態素解析の結果から、正規表現を使って品詞列を抜き出すためのパッケージmecabpr(mecab-pos-regexp)を作成しました。
概要
キーフレーズ抽出などのタスクにおいて、MeCabの形態素解析した文字列の中から「形容詞に続く名詞」や「任意の長さを持つ名詞の系列」といった特定のパターンを持つ品詞列を取り出したいことがあります。そのようなパターンを正規表現の記法を用いて表現し、一致する品詞列を抜き出すためのパッケージを作成しました。
ソースコード
使い方
インストール
mecabprはpipを使ってインストールできます。
$ pip install mecabpr
準備
mecabprを読み込みます。
import mecabpr
mpr = mecabpr.MeCabPosRegex()
sentence = "あらゆる現実をすべて自分のほうへねじ曲げたのだ。"
MeCabPosRegex()にはMeCabに渡すオプションを指定できますMeCabPosRegex("-d /path/to/mecab-ipadic-neologd")でNEologdの辞書を使うことができます
mpr.findall()の引数には、対象とする文字列と、正規表現で表した品詞列を指定します- 品詞には任意の階層を指定することができ、階層間を
-で区切って入力します (e.g.名詞-固有名詞-人名-一般)
- 品詞には任意の階層を指定することができ、階層間を
あとは、以下のように品詞のパターンを指定すると、目的の品詞列を取得できます。
例)「名詞」を抽出する
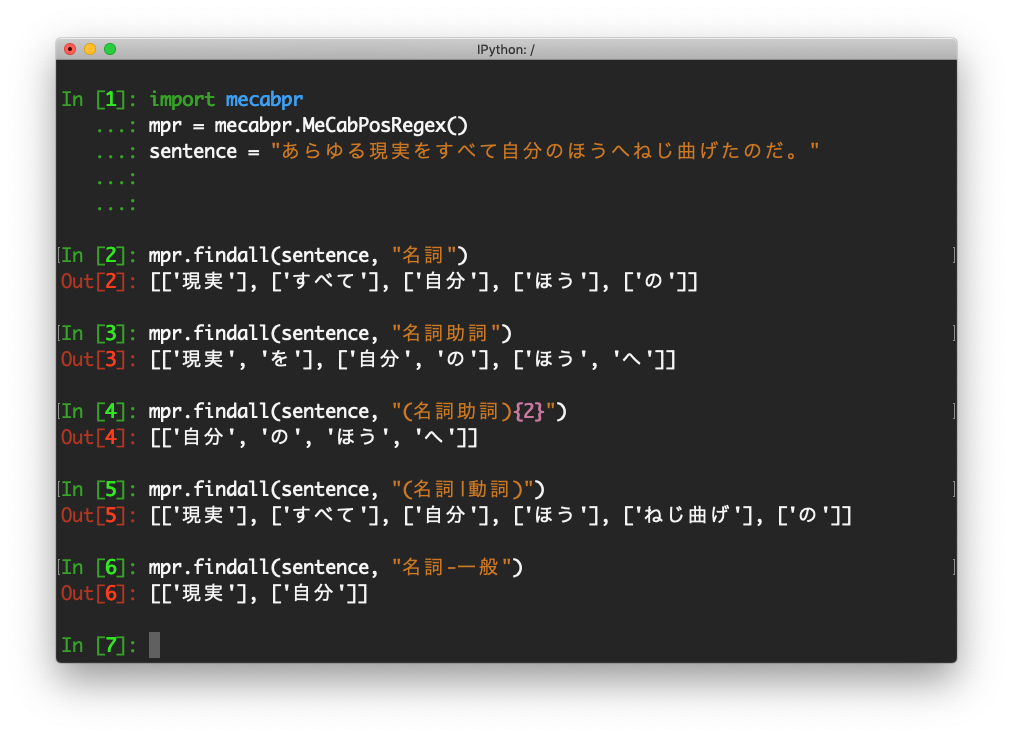
In []: mpr.findall(sentence, "名詞")
Out[]: [['現実'], ['すべて'], ['自分'], ['ほう'], ['の']]
例)「名詞に続く助詞」を抽出する
In []: mpr.findall(sentence, "名詞助詞")
Out[]: [['現実', 'を'], ['自分', 'の'], ['ほう', 'へ']]
ちなみに、"名詞助詞"のように一続きに表現しても問題ないですが、可読性のために"(名詞)(助詞)"のように品詞を括弧で括っても同様の結果が得られます。
例)「名詞に続く助詞が2回続くパターン」を抽出する
通常の正規表現と同様の記法を使うことができます。ここでは{2}を指定することで、2回の繰り返しを表現しています。
In [42]: mpr.findall(sentence, "(名詞助詞){2}")
Out[42]: [['自分', 'の', 'ほう', 'へ']]
例)「名詞または動詞」を抽出する
ここでは、正規表現に|を使って和集合を表現しています。
In []: mpr.findall(sentence, "(名詞|動詞)")
Out[]: [['現実'], ['すべて'], ['自分'], ['ほう'], ['ねじ曲げ'], ['の']]
例)「名詞-一般」を抽出する
正規表現で表した品詞列には、階層を表す分類も用いることができます。以下の例では、名詞の中でも一般であるものに限定して列挙しています。
In []: mpr.findall(sentence, "名詞-一般")
Out[]: [['現実'], ['自分']]
例)「名詞-一般に続く助詞」を抽出する
パターンを指定するときの品詞には、階層を表す分類を複数組み合わせることも可能です。その際に品詞の階層を合わせる必要はありません。以下の例では名詞-一般と助詞を組み合わせて正規表現を構成しています。
In []: mpr.findall(sentence, "名詞-一般助詞")
Out[]: [['現実', 'を'], ['自分', 'の']]
MeCabの出力をそのまま利用する
mpr.findall(raw=True)とすることで、出力を単語ではなくMeCabが出力した形態素解析結果の文字列に変更することができます。
In []: mpr.findall(sentence, "名詞助詞", raw=True)
Out[]:
[['現実\t名詞,一般,*,*,*,*,現実,ゲンジツ,ゲンジツ', 'を\t助詞,格助詞,一般,*,*,*,を,ヲ,ヲ'],
['自分\t名詞,一般,*,*,*,*,自分,ジブン,ジブン', 'の\t助詞,連体化,*,*,*,*,の,ノ,ノ'],
['ほう\t名詞,非自立,一般,*,*,*,ほう,ホウ,ホー', 'へ\t助詞,格助詞,一般,*,*,*,へ,ヘ,エ']]



