文書分類においてデータ内に現れる特定のパターンを見つける
2019-12-11

この記事はSansan Advent Calendar 2019 - Adventarの11日目の記事です。
概要
自然言語処理における教師有り学習では、対象となる文書から何らかの意味やパターンを見つけ、正解ラベルとの対応関係をモデルが学習することで、未知の文書に対するラベルの予測を行います。このとき、学習データの文書内に何らかの不適切な情報が混入することにより、意図せずモデルの精度が向上することがあります。これをリーク (Leakage)と呼び、自然言語処理のみならず機械学習が陥りやすい問題として広く認識されています。
2つの文章の意味の関係性(意味が同じか違うか)を推論するタスクで用いられているThe Stanford Natural Language Inference (SNLI)コーパスにおいては、特定のラベルにおいてある単語が多く現れやすいということが報告されています。例えば「nobody」や「no」などの否定形が入る文章は、3値分類のなかの「Contradiction(矛盾)」というラベルに多く含まれています。否定形があればとりあえずこのラベルに割り振れば正答率が高まるといったように、機械学習モデルが本来学習してほしい意味的な部分以外で答えを出してしまいかねないという問題があります。SNLIデータセットは人手で作成されていることからこのようなバイアスが生じており、こういった隠れた傾向を表す情報は Annotation Artifacts と呼ばれています。
https://www.aclweb.org/anthology/N18-2017/
今回は、自然言語処理においてリークとなるような、特定のラベルと強く関係している単語を見つける方法を紹介します。また、こういった人間が知る情報を使って前処理や評価を行う意義についても議論してみたいと思います。
自己相互情報量PMIによる特定パターンの抽出
今回は自己相互情報量(以降PMI)を使います。PMIは単語の共起を表す指標として自然言語処理で広く使われている方法です。このPMIを特定のラベルの特定の単語に対して計算することにより、そのラベルと強く関連している単語を抽出します。計算式としては以下のようになります。
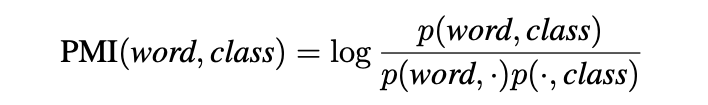 Img: Annotation Artifacts in Natural Language Inference Data (NAACL 2018) より
Img: Annotation Artifacts in Natural Language Inference Data (NAACL 2018) より
分子にはあるラベルの文書内に存在するある単語の頻度、分母には全ラベルの文書内に存在する単語の頻度と、ラベルの文書数があります。式の気持ちとしては、特定のラベルに偏った単語はp(word, class)とp(word, .)がほぼ同じようになるためPMIが大きくなり、全ラベルにまたがって存在する単語はp(word, class)よりもp(word,.)の方が大きくなるため、PMIが小さくなるようになっています。
このPMIは任意の単語に対して各ラベルぞれぞれに計算されるため、そのラベル間のPMIの値の差が大きいラベルとその単語に注目することで、リークと判断されうる単語や特性のパターンを確認することができます。
実験
「Livedoorニュースコーパス」を対象に、特定ラベルに現れるパターンを検知してみます。このコーパスは、「livedoor ニュース」が配信していたメディアのうち、9つのカテゴリのニュース記事本文が含まれています。
結果
Livedoorニュースコーパスのそれぞれのラベルに対して全単語のPMIを計算し、各ラベルのPMI平均との差が大きいそれぞれ上位3件の単語を以下に示します。
| label \ rank | 1 | 2 | 3 |
|---|---|---|---|
| dokujo-tsushin | オフィスエムツー | はるひ | ゆるっ |
| it-life-hack | 虎の巻 | イケショップ | 紺子 |
| kaden-channel | ビデオSALON | MIYUKI | KOMATSU |
| livedoor-homme | 求人情報 | type | @type |
| movie-enter | ベルセルク | ジョン・カーター | 映画批評 |
| peachy | 兼美 | 韓国コスメ | Write |
| smax | ICS | 開発コード名 | IceCream |
| sports-watch | 週刊アサヒ芸能 | すぽると! | サッカー解説者 |
| topic-news | 韓国ニュース | ビッグダディ | デヴィ夫人 |
具体事例
それでは、実際に上記の単語がどのように文書中に表れるかを見てみましょう。まずはdokujo-tsushinのPMI値が高い単語を文中から抽出してみます。
dokujo-tsushin「オフィスエムツー」「はるひ」の場合
杉本彩が言っていたっけ、「若いころに戻りたいとか、若く見られたい、とは思わない。今の自分がどう美しくあるかを追求したい」って。(オフィスエムツー/オオノマキ)
dokujo-tsushin/dokujo-tsushin-4788357.txt
絵本を読んでみたいが、どんな本が自分に向いているかわからないという人は、まず図書館の絵本コーナーへ行って見るといい。何冊も手に取る間に、自分の好みの絵やストーリーに出合えるはず。読み終えたとき気持ちが前向きになれる本がいい。(オフィスエムツー/神田はるひ)
dokujo-tsushin/dokujo-tsushin-4788373.txt
これを見ると「オフィスエムツー」というのは文末に現れる著者情報であることがわかります。この単語はdokujo-tsushinのラベルのなかの31.8%もの文章に含まれており、記事本文の内容とは無関係に記号的な用途として記載されていることがわかります。また「はるひ」も同様に、文末の著者名の一部でした。
dokujo-tsushin「ゆるっ」の場合
『結婚』よりも『結婚生活』を続ける方が難しい…!? Presented by ゆるっとCafe
dokujo-tsushin/dokujo-tsushin-5283348.txt
・『旦那に薬を盛りました』 著・森野いずみゆるっとCafe/竹書房 刊
dokujo-tsushin/dokujo-tsushin-5283348.txt
これらの単語はどうやら特定のメディア名の一部であることがわかります。「Presented by ゆるっとCafe」というフレーズは、このラベルの文書全体のうち7.4%程度に含まれていました。また、上記リストには掲載していないですが、上位には「Presented」という単語も含まれていました。こちらは一般的に使われる単語ではあるものの、ここでは他のカテゴリより頻繁に使われる単語として検知できています。
peachy「韓国コスメ」の場合
一方で、特定のパターンと呼ぶにふさわしくない単語もあります。peachyにおける「韓国コスメ」は以下のように文章中で使用されています。
日本で人気の韓国コスメ、今年は「カシコイ」マルチコスメが主流
peachy/peachy-4721837.txt
■その他の韓国コスメも要チェック!
peachy/peachy-4972021.txt
この「韓国コスメ」の場合は多くが文章中で使われており、特定のパターンとして出現しているわけではないことがデータセットを確認することでわかります。2つ目の特定フレーズ内で出現することもありますが、出現頻度や全体でのカバレッジを踏まえると、この単語自体は問題なさそうです。
特定フレーズと判断されたもの代表例
- dokujo-tsushin
- 「(オフィスエムツー/{著者名})」「Presented by ゆるっとCafe」
- it-life-hack
- 「■PC便利技が満載!「知っ得!虎の巻」ブログ」「【知っ得!虎の巻】」
- 「■【復活!イケショップのレアものがいっぱい】の記事をもっと見る」「【イケショップのレア物】」
- kaden-channel
- 「【ビデオSALON】」「■ビデオSALON イベント・製品レポート 最新記事」
- 「({著者名})」
- livedoor-homme
- 「livedoor求人・転職は、あなたがどんな求人情報を探しているのかを瞬時に判断しておすすめするコンテンツ。」
- 「(情報提供元:@type)」
- peachy
- 「■「Peachy」無料アプリ-iPhone-」「■「Peachy」無料アプリ-Android-」
- sports-watch
- 「・週刊アサヒ芸能[BookLive!]」「・週刊アサヒ芸能 [ライト版]」
- topic-news
- 「【韓国ニュース】」
議論 - リークか特徴量か?
ここまでで、文書分類においてリークとなりうる特定のパターンを抽出してきました。結果としては、意外と著者名や決まったフレーズが含まれており、文書の意味とは別の観点で文書分類のモデルが学習されうることが確認できました。
では、これらのリークとなるような単語や定型文は除去すべきでしょうか?また、どの程度の頻出度合いや傾向のものまで削除すべきでしょうか?
結論から言えば、これに対する明確な答えは存在しないというのが個人的な考え方です。より正確には、モデルを構築する人間が定めたタスクや、測りたい精度次第で答えが変わりうると思います。
例:モデルのベンチマークとして利用する場合
データセットはあくまでも評価として利用し、機械学習モデルの性能や機能が主軸に置かれている場合は、特に取り除く必要はないかもしれません。既存手法との比較においては相対的な数字の比較となるため、利用するデータセットや前処理などは揃えておくべきでしょう。特定のラベルに多く存在するフレーズも特徴量として活用して学習できる構造であれば、それを使って高い精度を出すこと自体に問題はないように思います。ただ、その結果を用いて「データセットが表現する意味を捉えて予測ができている」と結論付けるのには、少し疑問が残ります。
例:サービスとして運用し続ける場合
ではこれが実際のサービスやプロダクションで利用するモデルの場合はどうでしょうか?
手元にあるデータやその背後にある生成分布と、将来的に得られるものが同じ場合であれば問題はありません。今回のLivedoorニュースコーパスの例で言えば、
- 特定ラベルで付与される著者情報が将来的に変わらない
- 著者情報が記事末尾に付与されるというデータの性質が変わらない(途中から無くなったり文言が変わったりしない)
のであれば、特定のフレーズを取り除くことは必要ないかもしれません。しかし、実際にはそういうことが保証されないことの方が多いでしょう。自然言語処理においては、常に新しい未知語などが出現しますし、今回のような著者名やメディア名も変わりうると容易に想像できます。現在のトレーニングデータとテストデータにおいては高い精度が出せるモデルでも、今後そういったリークに該当する特徴量が未知のデータにおいてはその特徴量が得られないことにより、精度低下を引き起こすことが考えられます。逆に言えば、いまあるデータセットではモデルの精度を過大評価しているかもしれません。
一方で、こういった将来起こりうるデータセットの変化を正しく予測することはできません。また、どういった情報がリークなのかという判断や、それを見越した汎化性能を正しく評価することも難しいと考えられます。そこには常に人間の常識や予想が入り込むため、モデルの表現力や汎化性能という観点での扱いが難しいと感じます。
まとめ
この記事では、リークと呼ばれる特定のラベルと強く関係する単語やフレーズを発見する手法を紹介し、実際にLivedoorニュースコーパスで検証しました。この手法を使うことによって、モデルに学習してほしくない単語や特定のフレーズを取り除くことができます。一方で、こうした人間の解釈が伴う前処理はその意義や目的が明確でないと扱いが難しく、万能な正解が存在しないことも注意が必要です。



