深層学習時代の言語判定の最新動向
2019-05-05

概要
言語判定(Language identification)とは、与えられた文字列が何語で書かれているかを判定するタスクです。例えば「こんにちは」なら日本語、「Hello World.」なら英語といったように、世界各国で話されている言語のうち何に属するかを推定するというものです。
これだけ聞くと非常に簡単な問題のように思えますよね。出てくる単語を辞書で探せば何語か分かりそうなものですし、書かれている文字を見ても容易に判別できそうな気がします。Google翻訳のような機械翻訳が高精度に文章を翻訳できる現在において、言語を判定するなんて行為はより基本的なことで、できて当たり前とも思えます。実際に2010年時点でサイボウズ・ラボの中谷さんが作成された言語判定エンジンlanguage-detectionは、49言語で99.77%の正解率で判定することができています(source)。他の言語処理タスクでは考えられないくらい高い正解率ですし、ここからの向上余地なんてほぼ無いんじゃないかと考えてしまいます。
しかしながら、言語判定は今でも様々な論文が発表される分野です。極端な例を出すならば、Googleは自然言語処理において1st tierな学会であるEMNLPで2018年に言語判定の論文を出しています。このように現在でも研究され論文が通る分野であり、大学のみならず企業からも論文が発表される領域です。では、どこに研究の課題が残されているのでしょうか?また近年大きく発展した深層学習は、言語判定にどのように影響しているのでしょうか?
ここでは、近年発表された3種類の言語判定の論文をもとに、深層学習時代の言語判定について見ていきたいと思います。
複数の言語が混ざった文章の言語判定
A Fast, Compact, Accurate Model for Language Identification of Codemixed Text
まずは冒頭でも紹介したEMNLP 2018のGoogleの論文です。論文タイトルにあるように複数言語が混ざった文章を対象にした言語判定は、既存の言語判定モデルでは無視されてきた領域でした。特にユーザが投稿するようなサービスにおいては同じメッセージを複数言語で記載することが多く、そのような言語判定に対応するため、より粒度の細かい単位で言語判定することが必要となります。
例えば、以下のようなTweetはその代表例でしょう。
新しい御代の幕開けに心からお祝い申し上げます。『令和』が日本の国に平和と繁栄をもたらす祝福された時代となるよう祈念致しております。🇯🇵 Congratulations on the beginning of the new era! We hope 令和 will be blessed with peace and prosperity for everyone in Japan.
— Tim Cook (@tim_cook) April 30, 2019
この論文で提案している手法CMXは、まずトークン(単語)単位で言語判定をしたのちに、貪欲法を用いて文章全体での言語判定を行うというものです。前半の言語判定には文字特徴量とトークンの特徴量の両方を用いたシンプルなニューラルネットワークを用いています。
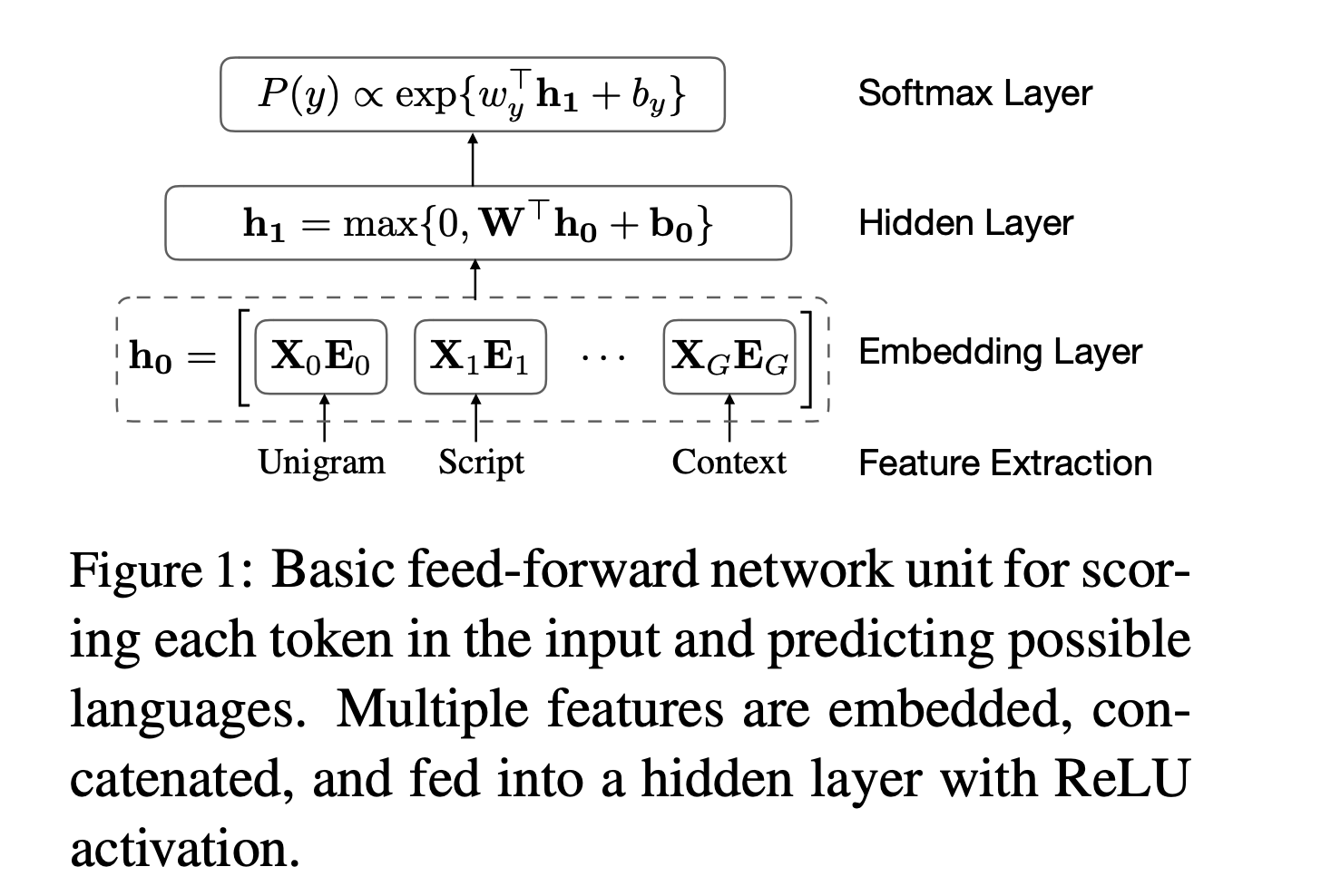 (Ref. https://arxiv.org/abs/1810.04142)
(Ref. https://arxiv.org/abs/1810.04142)
文字特徴量は従来の言語判定と同じように文字n-gramを用いており、n=[1,4]を計算したのちにfeature hashingで語彙数をコントロールしています。これは、n-gramのnを増やすごとに生成される文字列のパターン数が指数的に増加することから、計算コストやモデルサイズを削減するためです。その他にも、ひらがなやハングルのように特定文字に対応する言語の特徴量や、辞書ベースの特徴量などを加えたモデルになっています。
単語や文字単位での言語判定
LanideNN: Multilingual Language Identification on Character Window
単一文章に対して複数言語を判定できるようになれば、次に知りたくなるのは文章中での言語の出現位置や、どこで言語が変わったかといった文章内の情報です。さきほどのGoogleの論文ではトークン単位で推定しつつ全体の文章の言語判定をしていましたが、EACL 2017で発表されたLanideNNでは入力文を文字単位で言語判定するモデルを提案しています。
 (Ref. https://arxiv.org/abs/1701.03338)
(Ref. https://arxiv.org/abs/1701.03338)
提案モデルは文字を入力にしたBidirectional RNNを構成し、それぞれの文字に対して言語を予測するモデルになっています。長い文章の場合は、特定のwindow sizeごとにモデルから予測を出力し、windowをずらしながら文章全体をカバーするよう予測していきます。
LanideNNは実装や学習済みモデル、データセットも公開されています。
より多様な言語に対応した言語判定
Incorporating Dialectal Variability for Socially Equitable Language Identification
これまでの言語判定は複数言語に対応しつつもモデルの精度を下げないことが目標でしたが、ACL 2017のEquilidではより社会的に公平性を保つよう、マイナーな言語や方言に対応できる言語判定モデルを作成しています。
既存の言語判定モデルがコーパスを作成する際には、研究の主流であるヨーロッパ系の言語が主体となっていたり、Wikipediaなどのウェブソースでは人口が多い言語で書かれた文章が手に入りやすい環境であることにより、どうしても主要な言語で精度が出せることが重要でした。この論文では、地理的であったり社会的な多様性を考慮したコーパスを作成し、かつモデルもそうした細かな差異を認識できるよう工夫しています。
モデルはLanideNNと同様に文字ベースのニューラルネットを採用しており、綴りや音韻といった要素をモデルに組み込むことを意図していると論文では述べられています。言語判定はトークン単位で行われます。ニューラルネットについてはAttention付きのencode-decoderモデルで、encoderとdecoderはそれぞれ3-layerのRNNです。
Equilidは実装や学習済みモデルも公開されており、配布されている学習済みモデルでは70言語に対応しているようです。
まとめ
これまで最新の深層学習を用いた言語判定をいくつか見てきました。これらに共通する特徴としては、単語や文字単位で言語判定を行い、より複雑な言語特徴が得られるようなモデルを作成するように変化していることが分かります。
ニューラルネット以前の言語判定の多くは文字n-gramの頻度などを特徴量として判定しており、精度を上げるためにはなるべく文章全体で文字n-gramを計算する必要がありました。n-gramのnを増やせば増やすほど長い系列を捉えることは可能になりますが、一方で特徴量の次元数が増大しスパースになるといったトレードオフが存在します。それが深層学習の発展によってニューラルネットが文字列の系列情報を上手く利用することができるようになり、従来の文章単位から単語や文字単位へ拡張することが可能になったと考えられます。
言語判定を取り巻く環境は、近年のSNSなどの登場でより複雑な言語判定の問題を解く必要性が生じ、深層学習の登場でより細かな粒度での言語判定が可能になりました。単一言語では100%近い精度が出る言語判定ですが、GoogleのCMXでは特定の複数言語のペアに限定した上での判定の精度が平均で93%程度と、精度や実課題への適用においてはまだまだ発展の余地が残されている分野であると言えます。
参考
深層学習以前の言語判定については、サイボウズ・ラボ中谷さんが書かれた言語判定の解説記事や書籍を参照ください。



