A La Carte Embeddingの実装
2018-12-07

ACL2018にて発表された“A La Carte Embedding: Cheap but Effective Induction of Semantic Feature Vectors”を実装しました。未知語やngramなどの単語埋め込みを既知の学習済みベクトルから計算する手法です。
この記事はSansan Advent Calendar 2018 の8日目の記事です。
概要
“A La Carte Embedding"は、文脈における周囲の単語埋め込みを平均したものが学習済みの単語埋め込みと一致するように線形変換を学習することで、未知語に関しても単語埋め込みのベクトルを推定する手法です。これにより、通常の単語埋め込みでは学習が難しいような低頻度語であったり、複合名詞などの複数の単語からなる語においても、分散表現を得ることができます。
本論文の著者らは、これまでにSIF Embeddingなど理論寄りな方面から単語埋め込みや文章のベクトル表現を研究しているプリンストン大学のSanjeev Aroraのグループです。
ロジック
A La Carte Embeddingに必要なのは、大規模コーパスと学習済みの単語ベクトルです。
学習の流れとしては、
- 単語埋め込みを計算したい低頻度語やngramなどの語彙を用意する
- 学習済みの単語埋め込みの語彙と1.で用意した語彙を対象に、学習コーパス内で文脈内に存在する単語埋め込みの和や出現数から文脈における埋め込みを得る
- これらのうち学習済みの単語埋め込みに関しては正解がわかっているので、2.で作成した文脈における埋め込みのがこの正解と一致するような線形変換を学習する
- 学習した線形変換を利用して、2.で計算した低頻度語やngramなどのベクトル表現に関しても線形変換を行って単語埋め込みを得る
という感じです。
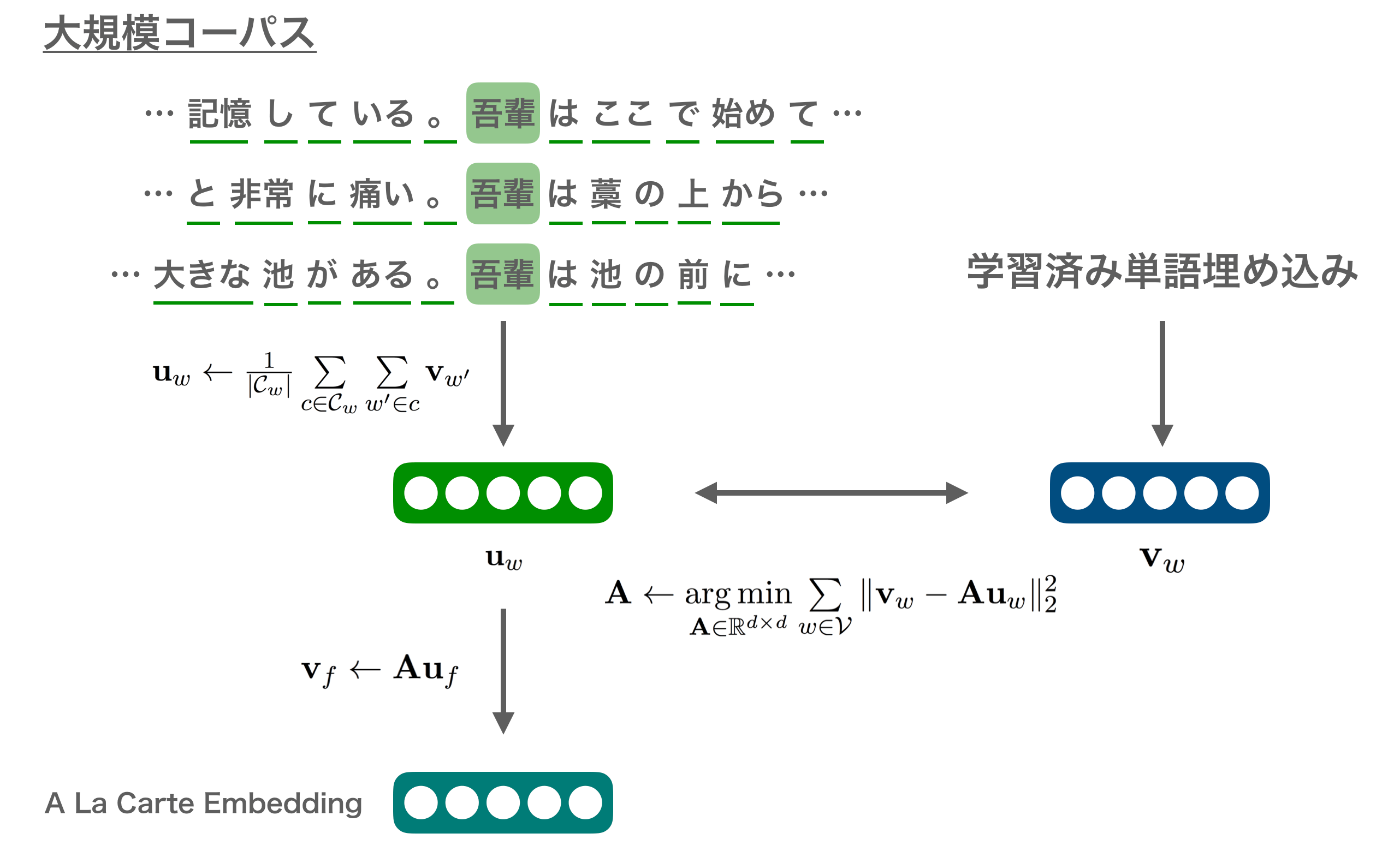
例えば("単語","埋め込み")というbigramのベクトル表現を得たいと思ったとしたら、コーパス内でこのbigramの周囲の単語埋め込みのベクトルを足し合わせてその出現頻度で割ることで、2.の文脈埋め込みが得られます。なお、ここで言う文脈はword2vecと同じく、特定のウィンドウ幅に含まれる単語の集合のようなものです。それをコーパス内で先頭から順に、すべての語彙で行います。線形変換の学習には、既知の単語埋め込みにある単語ベクトル(上図でいう吾輩のような既知の単語など)と、今回作成した文脈埋め込みが等しくなるように学習させます。あとはこの線形変換をbigramの文脈埋め込みに掛けることによって目的とするベクトル表現が得られます。
ソースコード
yagays/alacarte_embedding: Python implementation of A La Carte Embedding
なお、本ソースコードで精度評価やオリジナル実装との比較は行っていません。バグや細部の実装の違いが含まれている場合がありますのでご注意ください。
オリジナルの実装
著者らがオリジナルの実装を公開しています。こちらは(当然ながら)スペースで単語が分割できる英語などの言語を対象にしています。
使い方
ALaCarteEmbeddingを作成し、コーパスに対して実行します。パラメータは以下の通りです。
- word2vec: 学習済み単語埋め込み
- gensimの
Word2VecKeyedVectorsを前提としています
- gensimの
- tokenize: トークナイザ
- min_count: 対象とする単語のコーパス内での頻度の最小値
- ngram: 対象とするngram
alc = ALaCarteEmbedding(word2vec=w2v,
tokenize=tokenize,
min_count=10,
ngram=[1, 2])
alc.build(documents)
類似する単語を推定するにはmost_similar()を利用します。ngramの場合はタプルで入力します。
alc.most_similar("query")
alc.most_similar(("bigram", "query"), topn=10)
学習したA La Carte Embeddingをsave()で保存します。
alc.save("path/to/model.txt")
結果
実際にwikipedia(ja)のデータで学習させ、幾つかの単語に類似する単語を表示した結果です。
| 入力した単語 | 類似する単語(近い順) |
|---|---|
| 2010年 | 2009年, 2012年, 2008年, 2011年, 2013年, 2007年, 2006年, 2014年, 2011, 2006 |
| 石油産業 | 重工業, 軍需産業, 主要産業, 輸出産業, 綿花栽培, 工業, 大量消費, カルチャー経済, 農業技術, 商工業 |
| 人口増加 | 人口減少, 増加傾向, 人口集中, 減少傾向, 労働人口, 人口, 高齢化, 沿線人口, 都心回帰, 落ち込み |
| 通信ネットワーク | 衛星通信, 通信システム, データ通信, データセンター, ブロードバンドインターネット, ブロードバンド, PSM, 機能強化, メーカ, DDR |
| ハイスコア | スコア, スコアアタック, パーフェクトゲーム, 2ゲーム, おじゃま, 各ゲーム, パーフェクト, プレイ可能, 面クリア, テーブルゲーム |
| 劇場アニメ | TVドラマ, 映画化, スピンオフ, 年公開, 特別篇, 後継作品, 映画社, ファウンデーション, ファンタジー小説, 世紀フォックス |
かなりいい感じになっているのではないでしょうか。上の表記ではngramの単語列について結合して表示しているので少しわかりにくいですが、「人口減少」「増加傾向」「衛星通信」「通信システム」「スコアアタック」「後継作品」などbigram由来のものも含まれています。
今回の実験条件として、Wikipediaのコーパス(計算量の都合上10万文章ほど)における頻度が10以上のunigramおよびbigramすべてを対象に、A La Carte Embeddingを計算しました。形態素解析にはMeCabおよびmecab-ipadicを利用しました(NEologdは利用していません)。類似する単語の列挙の際には、句読点や接続詞、記号などが含まれるbigramは除去し、名詞などから構成される単語列を利用しました。
まとめ
今回はACL2018で発表されたA La Carte Embeddingを実装して簡単な実験を行いました。ngramなどの任意の単語の組み合わせに対して埋め込み表現を学習できる点がとても興味深いです。ある程度のコーパスが必要になりますが、非常に強力な手法なのではないかと思います。
意味のあるまとまり単位で特定のキーワードのような単語や単語列を抜き出したいというケースは往々にしてあるので、そういった際に使える手法かと思います。あとは言い換えやデータ拡張などにも適用できそうです。
まだあまりちゃんとした実験できていないのですが、深掘りするといろいろと応用が見つかりそうです。あらかじめ頻出するbigram/trigramを網羅的に学習させておいて、それを学習済み分散表現として利用するというのも面白い気がします。
参考
- Simple and efficient semantic embeddings for rare words, n-grams, and language features – Off the convex path
- NLPrinceton/ALaCarte
- A La Carte Embedding: Cheap but Effective Induction of Semantic Feature Vectors on Vimeo
- alacarte-snlp2018 - Speaker Deck
- A La Carte Embedding: Cheap but Effective Induction of Semantic Feature Vectors - 長岡技術科学大学 自然言語処理研究室



